2.3 Validation
Of all the steps involved in the QTA workflow, validation is often the one that receives the least attention. However, given that each method is based on some form of machine learning, it is also the most important. In fact, Grimmer & Stewart (2013) advised to “validate, validate, validate!”. The reason is simple. With the large amount of data and the fact that we are simply counting numbers, it is very easy to find evidence for something, especially when it is (very) large data. We should therefore be very sure of what we are doing and whether it makes sense. For this reason, it is a good idea to take a closer look at what validation actually means and how to go about it.
Validation involves two related concepts: reliability and validity. Here, reliability refers to our measure’s consistency (or stability). If we have a measure with high reliability, this means that we should get the same results each time we run it - it is stable and not prone to random error or variation. Validity, on the other hand, refers to the accuracy or appropriateness of our measure. In other words, if our measure is valid, we measure what we want to measure. If you want to think about it in statistical terms, reliability is the proportion of non-random variance, while validity is the proportion of variance that the observed scores share with the true scores.
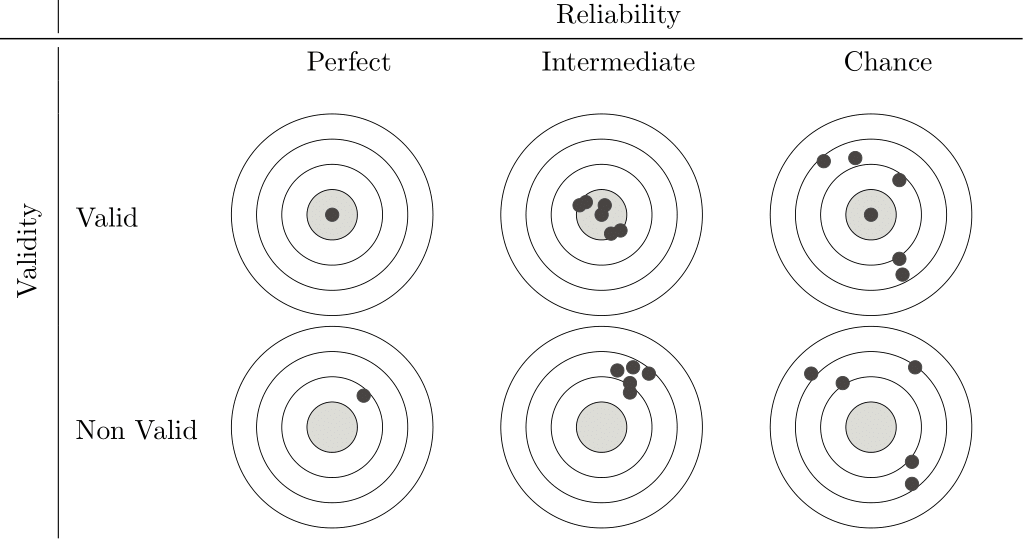
Figure 2.1: Validity and Reliability
Note that reliability and validity are not mutually exclusive. There is no point in having a highly valid measure that is not reliable, or a highly reliable measure that is not valid. Figure 2.1, after Krippendorff (2019), shows this nicely by comparing our measure with a target, with the hits (the black dots) representing individual measures. What we are aiming for is at the top left: a measurement that hits the target perfectly every time. However, as our reliability decreases, more and more often we are not only hitting the target, but also hovering around it. As a result, high validity but low reliability means that sometimes we hit the target, but whether we do so is a matter of chance. At the same time, high reliability but low validity means that we hit the same spot every time, but always miss the target. So we never measure what we want to measure. So we want our measure to be both valid and reliable if it is to be of any use. Now, let’s look at both concepts in a little more detail.
2.3.1 Validity
Of the two concepts, validity is the more difficult. To understand it a little better, we can divide it into three subtypes: content, criterion, and construct validity (Carmines & Zeller, 1979). Each of these focuses on a different aspect of validity and has different issues associated with it.
| Content Validity | Does our measure cover all the aspects or dimensions of the concept we are studying? For example, if we design a coding scheme to measure ‘political ideology’, have we included all the different attitudes to existing economic, social and foreign policy issues? To see if this is the case, we often rely on expert judgement and our own theoretical understanding of the concept. |
| Criterion Validity | How well does our measure correlate with other established measures of the same concept? For example, we might test whether a sentiment score we get from social media texts agrees with the results of a public opinion poll on the same topic. Another way might be to use our measure to predict a future outcome and then check that the prediction is correct. For example, we could see if the amount of attention given to specific policies in legislative debates could help us predict future budget allocations for those policies. |
| Construct Validity | How well does our measure operationalise our concept? If it does, we would expect the measure to behave in the same way as the concept. For example, if we develop a measure of “economic uncertainty” from news articles, we would expect it to be negatively correlated with measures of consumer confidence. |
So, how do we put this into practice? One aspect that generally makes validity more difficult than reliability is that there is very little we can measure. Instead, we have to argue and prove, using a variety of methods, that our measure and overall analysis are indeed valid.
The most common approach is to compare against a gold standard. For example, suppose we have access to a human-coded dataset for a subset of our data. In this case, we can compare the output of our (computational) method with these human judgments. Indeed, this is what we will do in Chapter 7, where we will use this to calculate metrics such as accuracy, precision, recall and F1 scores. Related to this is when we use our data to predict other (external) data. For example, we might build a model to explain the overall economy of a country, and then relate this to the country’s actual GDP. Somewhat more complicated is when we focus on our analysis’s actual meaning. This involves asking whether the results generated by our method are conceptually meaningful and make sense to people. In sentiment analysis, for example, we could manually review examples where our model gives strong positive or negative sentiment scores and see if they make sense. Preferably, we would have more than one person do this to avoid being too lenient on the model.
Ideally, we would use as many validation options as possible (a technique also known as triangulation). This way, with each validation, we build confidence and strengthen our argument that our approach is valid.
2.3.2 Reliability
Reliability, as we saw above, is whether our measurement measures the same thing each time we do it, or, more broadly, whether our analysis would lead us to the same conclusions each time. One thing that helps us here is that reliability is something we can measure (unlike validity). It often comes in three forms: stability, reproducibility and accuracy. The first, Stability, refers to how consistent a measurement is over time. For example, if we asked a coder to code the same text on different occasions, we would expect them to code it the same way (also known as within-coder consistency). The second, Reproducibility (also known as inter-coder reliability), extends this to multiple coders. This means that independent coders, given the same coding instructions, should produce the same code for the same text. Finally, the third, Accuracy (which we also use for validity), compares our coders’ codes to a known standard or “true” value. The better the comparison, the more reliable our measure.
The first type - stability - is easy to measure: just repeat the analysis and compare the results. The second - reproducibility - is more complicated. This is because there are several things we want to be able to take into account, such as the ability to account for the categories our coders actually use, a standardised scale for interpretation, appropriateness to the level of measurement of our data (e.g. nominal, ordinal, interval, ratio), correction for chance agreement, and the ability to handle missing data. There are several measures of reproducibility, each with its own strengths and limitations. The simplest and most straightforward is Percentage Agreement, where we divide the number of codes the coders agree on by the total number of codes coded. However, this does not consider agreement that could occur purely by chance, therefore overestimates reliability.
Another way of doing this is to use Pearson’s correlation coefficient (r), as we would assume that we are correlating the codes of one or more coders. However, Pearson’s r measures linear association, not agreement. Thus, two coders can be in perfect disagreement and still show a strong positive or negative correlation if their disagreements follow a consistent linear pattern.
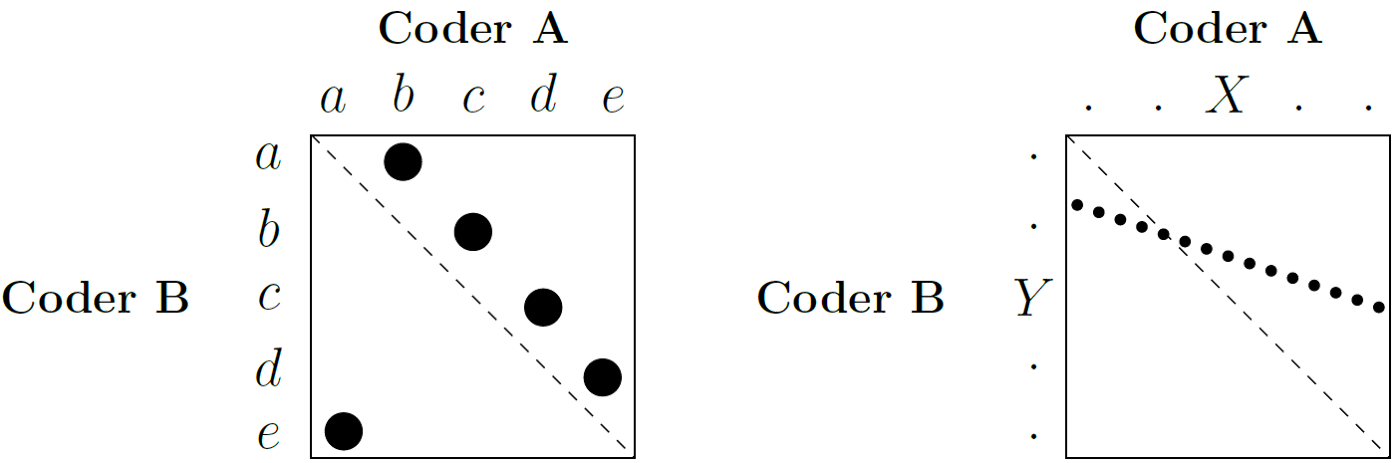
Figure 2.2: Perfect agreement between two coders
Consider Figure 2.2, which is an example adapted from Krippendorff (2019) to illustrate this. Suppose we have two coders, A and B, each assigning sentences to five categories, labelled ‘a’ to ‘e’. If, for example, whenever Coder A assigns ‘a’, Coder B assigns ‘e’; and whenever Coder A assigns ‘b’, Coder B assigns ‘a’, and so on, they are in perfect disagreement (the example on the right). However, if we calculated Pearson’s r, we might still find a high correlation. This is because Pearson’s r only looks at the distances between the values, regardless of their location. For there to be a correlation, it is only necessary for increases or decreases in the category values assigned by one coder to be mirrored by similar directional changes in the other’s assignments, a condition that can be met even when there is complete disagreement about the actual categories assigned. For this reason, we generally do not recommend it. Instead, we have the following options:
Cohen’s \(\kappa\) is useful for assessing agreement between two coders on nominal (categorical) data. It improves on percent agreement because it corrects for chance agreement, based on each coder’s individual marginal distributions of codes.
Scott’s \(\pi\) is similar to Cohen’s \(\kappa\), but we use it when we assume that the two coders are drawing from the same underlying distribution of codes. Consequently, it calculates the chance agreement based on the pooled marginal distribution of codes. Like Cohen’s \(\kappa\), we use it with two coders and nominal data.
Fleiss’ \(\kappa\) is an extension of Scott’s \(\pi\) . We use it when assessing the agreement between multiple coders (more than two) on nominal data. A key requirement for Fleiss’ \(\kappa\) is that each unit (e.g. document, sentence) must be coded by the same number of coders, although it does not necessarily have to be the exact same set of coders for each unit.
Since each of these three measures has its drawbacks, we will use Krippendorff’s \(\alpha\) here. It improves on the other measures by handling any number of coders, allowing for missing data, and applying to any level of measurement - nominal, ordinal, interval, and ratio. In addition, it calculates the random agreement based on the observed data, rather than assuming any distribution.
We can calculate Krippendorff’s \(\alpha\) using the formula:
\[\alpha = 1 - \frac{D_o}{D_e}\]
Where \(D_o\) is the disagreement we observe between the coders, determined by the distance function we choose to be appropriate for the level of measurement of our data. \(D_e\) represents the disagreement we would expect by chance, calculated from the distribution of codes assigned by our coders. Thus, if we obtain a \(\alpha\) value of \(1.0\), this indicates perfect agreement; \(0.0\) indicates agreement at the level of chance alone; and a value below \(0.0\) indicates systematic disagreement between our coders. For interpretation, we follow Krippendorff’s suggestion that a \(\alpha \ge 0.800\) indicates good reliability, while values between \(0.667 \le \alpha < 0.800\) may allow us to draw tentative conclusions. We usually consider alpha values below \(0.667\) to indicate poor reliability.
However, even \(\alpha\) has its limitations, the most problematic being when coders agree on only a few categories and use those categories very often. This inflates the value of \(\alpha\), making it higher than it should be.

Figure 2.3: Inflation caused by use of a limited number of categories
Figure 2.3 (based on Krippendorff (2019)) illustrates this point. Imagine a coding task with three categories (\(0\), \(1\) and \(2\)). Category \(0\) indicates that the coders could not assign a more specific code, while categories \(1\) and \(2\) represent meaningful codes. If, out of a large number of cases (e.g. \(86\)), both coders assign category \(0\) to the majority (e.g. \(80\) cases), this leaves very few cases for us to observe agreement or disagreement on the meaningful categories \(1\) and \(2\). If we then calculate \(\alpha\) over all three categories, we get a moderate value (\(0.686\)). However, if we then collapse categories \(1\) and \(2\) into a single category ‘meaningful code’, distinguishing only between ‘meaningful code’ and ‘no meaningful code’ (category \(0\)), the agreement on this broader distinction suddenly becomes very high, leading to a higher \(\alpha\) (\(0.789\)). On the other hand, if we remove the dominant \(0\) category and calculate \(\alpha\) only on categories \(1\) and \(2\) (for the few cases where they were used), the resulting \(\alpha\) could be very low (almost \(0\)). This could happen if a coder did not use one of these categories at all, even if they agreed on the other meaningful category in the remaining cases. This shows how our choice of categories to include in the calculation, and their observed distribution, can significantly influence the resulting \(\alpha\) value.
Finally, \(\alpha\) depends on our chosen metric (e.g. nominal, ordinal, interval, ratio). If we use an inappropriate metric, such as a nominal metric for data that is actually ordinal, we may ignore valuable information about the ordered nature of the categories, leading us to misunderstand the actual level of agreement achieved by our coders.
To calculate \(\alpha\) in R, we use the irr package, which provides the kripp.alpha() function. To see how this works, we simulate a case where \(12\) coders code \(10\) sentences into \(3\) categories:
library(irr) # Load the library
set.seed(24) # Setting a seed makes our example reproducible
# We create a matrix with 10 coders (rows) coding 12 sentences (columns) into 3
# categories (1, 2, or 3)
reliability_matrix <- matrix(sample(1:3, 10 * 12, replace = TRUE), nrow = 10, ncol = 12)
# Now, we calculate Krippendorff's alpha, specifying the data and method (level
# of measurement). For this example, we assume nominal data.
k_alpha_nominal <- kripp.alpha(reliability_matrix, method = "nominal")
print(k_alpha_nominal)## Krippendorff's alpha
##
## Subjects = 12
## Raters = 10
## alpha = 0.0106When we run kripp.alpha, the output typically includes the calculated \(\alpha\) value, the number of units (which it refers to as subjects), the number of coders (raters), and the level of measurement we specified for the calculation (e.g. “nominal”). We then compare this resulting \(\alpha\) value with established thresholds (e.g. \(0.67\) or \(0.80\), as Krippendorff suggests) to assess our coding reliability. For a more nuanced understanding of the stability of our estimate, we can obtain bootstrapped confidence intervals for \(\alpha\) using packages such as kripp.boot (see here).
In addition, we can also visualise our reliability. One way of doing this, adapted from Benoit et al. (2009) and Lowe & Benoit (2011), is to use bootstrapping to estimate and visualise the uncertainty around each coder’s distribution of codes across the different categories. To do this, we first obtain the number of times each coder used each specific category. Then, for each coder, we use their observed coding patterns (i.e., the proportion of times they used each category) to repeatedly resample their codings, typically using a multinomial distribution. From these numerous bootstrapped samples, we compute summary statistics such as the mean percentage and standard error for each category for each coder. Finally, we plot these mean percentages along with their confidence intervals. This allows us to visually represent the consistency of each coder and identify any significant variation in their application of the coding scheme. As before, let’s simulate the coding output of 12 coders across 3 categories and see how this works:
library(dplyr)
library(tidyr)
library(ggplot2)
set.seed(48)
# Create placeholder data to simulate coder output. This tibble will have coder IDs and counts for three hypothetical categories (c00, c01, c02)
data_uncertainty <- tibble(
coderid = 1:12,
c00 = rpois(12, 50), # Simulating counts for category 0
c01 = rpois(12, 20), # Simulating counts for category 1
c02 = rpois(12, 10) # Simulating counts for category 2
) %>%
mutate(n = c00 + c01 + c02) # Total codes per coder
category_cols_id <- c("c00", "c01", "c02")
# Now, we perform the bootstrap
n_coders <- nrow(data_uncertainty)
n_repl <- 2000 # We set the number of bootstraps
n_categories <- length(category_cols_id)
# We prepare an array to store our bootstrap results: coder x category x replicate
bootstrap_results_array <- array(
NA,
dim = c(n_coders, n_categories, n_repl),
dimnames = list(data_uncertainty$coderid, category_cols_id, 1:n_repl)
)
# We loop through each coder to resample their codings.
for (coder_idx in 1:n_coders) {
observed_counts <- as.numeric(data_uncertainty[coder_idx, category_cols_id])
total_codes_n <- data_uncertainty$n[coder_idx]
observed_probs <- observed_counts / total_codes_n
# We ensure probabilities sum to 1
if (abs(sum(observed_probs) - 1) > 1e-6) {
observed_probs <- observed_probs / sum(observed_probs)
}
# We perform multinomial resampling
resampled_counts_matrix <- rmultinom(n = n_repl, size = total_codes_n, prob = observed_probs)
bootstrap_results_array[coder_idx, , ] <- resampled_counts_matrix
}
# We convert counts to percentages
bootstrap_percentages_array <- sweep(
bootstrap_results_array,
MARGIN = c(1, 3),
data_uncertainty$n,
FUN = "/"
) * 100
# Handle potential NaN if a coder had 0 codes for 'n'
bootstrap_percentages_array[is.nan(bootstrap_percentages_array)] <- 0
# Calculate summary statistics
mean_perc <- apply(bootstrap_percentages_array, c(1, 2), mean, na.rm = TRUE)
# Use the SD of the bootstrapped means as an estimate of the standard error
sd_perc <- apply(bootstrap_percentages_array, c(1, 2), sd, na.rm = TRUE)
mean_perc_df <- as.data.frame.table(mean_perc, responseName = "mean_p") %>%
rename(coderid = Var1, category = Var2)
sd_perc_df <- as.data.frame.table(sd_perc, responseName = "se_p") %>%
rename(coderid = Var1, category = Var2)
vis_data <- full_join(mean_perc_df, sd_perc_df, by = c("coderid", "category")) %>%
mutate(
lower_ci = mean_p - 1.96 * se_p, # 95% CI lower bound
upper_ci = mean_p + 1.96 * se_p, # 95% CI upper bound
lower_ci = pmax(0, lower_ci), # Ensure CI doesn't go below 0%
upper_ci = pmin(100, upper_ci), # Ensure CI doesn't exceed 100%
coderid = factor(coderid) # Treat coderid as a factor for plotting
)
# Finally, we plot the three categories:
categories_to_plot <- category_cols_id[1:min(3, length(category_cols_id))]
plots_list <- list() # To store plots if we generate multiple
for (cat_to_plot in categories_to_plot) {
plot_data_subset <- filter(vis_data, category == cat_to_plot)
p <- ggplot(plot_data_subset, aes(x = mean_p, y = coderid)) +
geom_point(size = 2) +
geom_errorbarh(aes(xmin = lower_ci, xmax = upper_ci),
height = 0.2,
na.rm = TRUE) +
scale_x_continuous(name = "Mean Percentage Coded (%) with 95% CI", limits = c(0, NA)) +
scale_y_discrete(name = "Coder ID") +
ggtitle(paste("Our Analysis of Coder Usage for Category:", cat_to_plot)) +
theme_classic()
plots_list[[cat_to_plot]] <- p
print(p) # Display the plot
}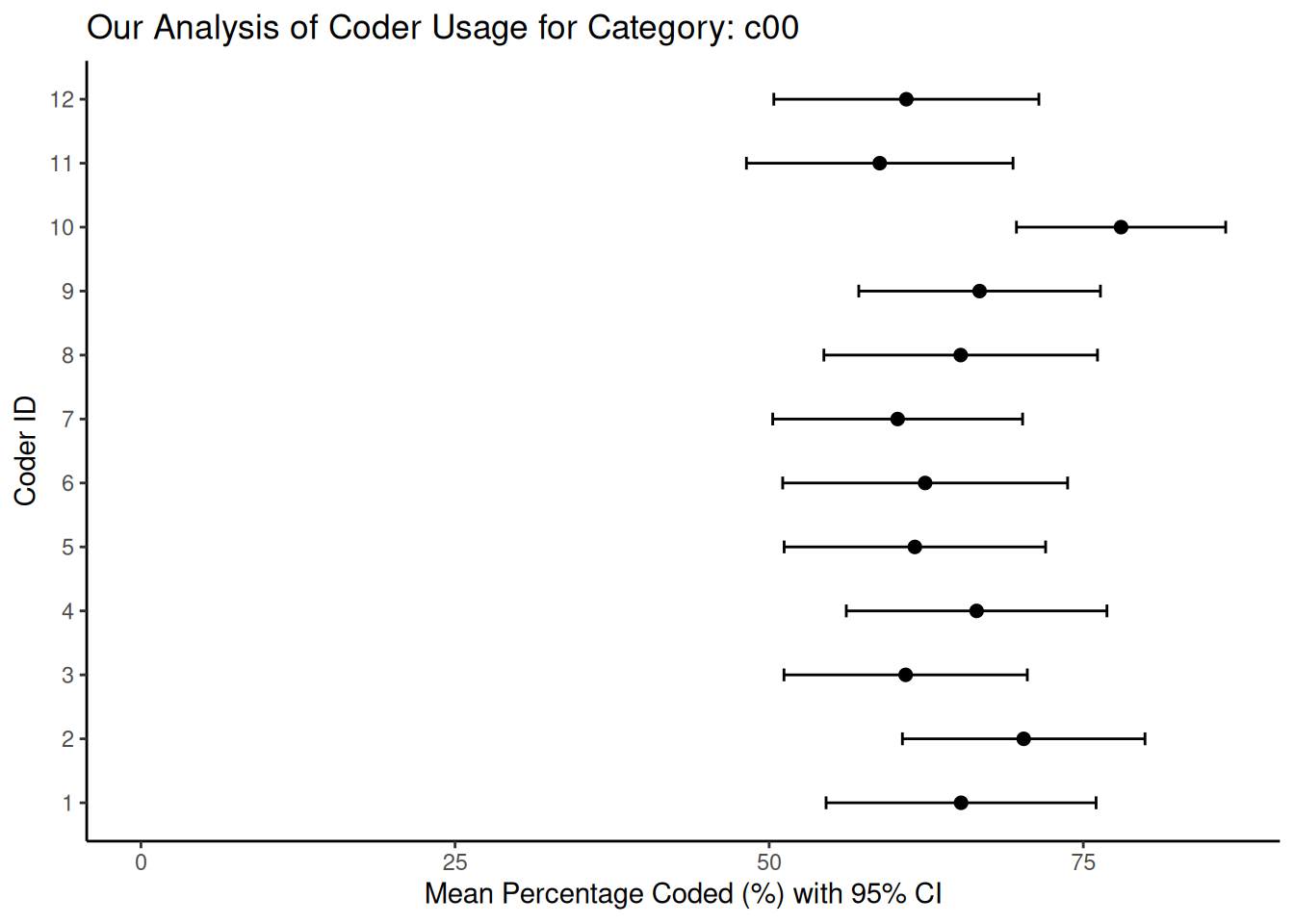
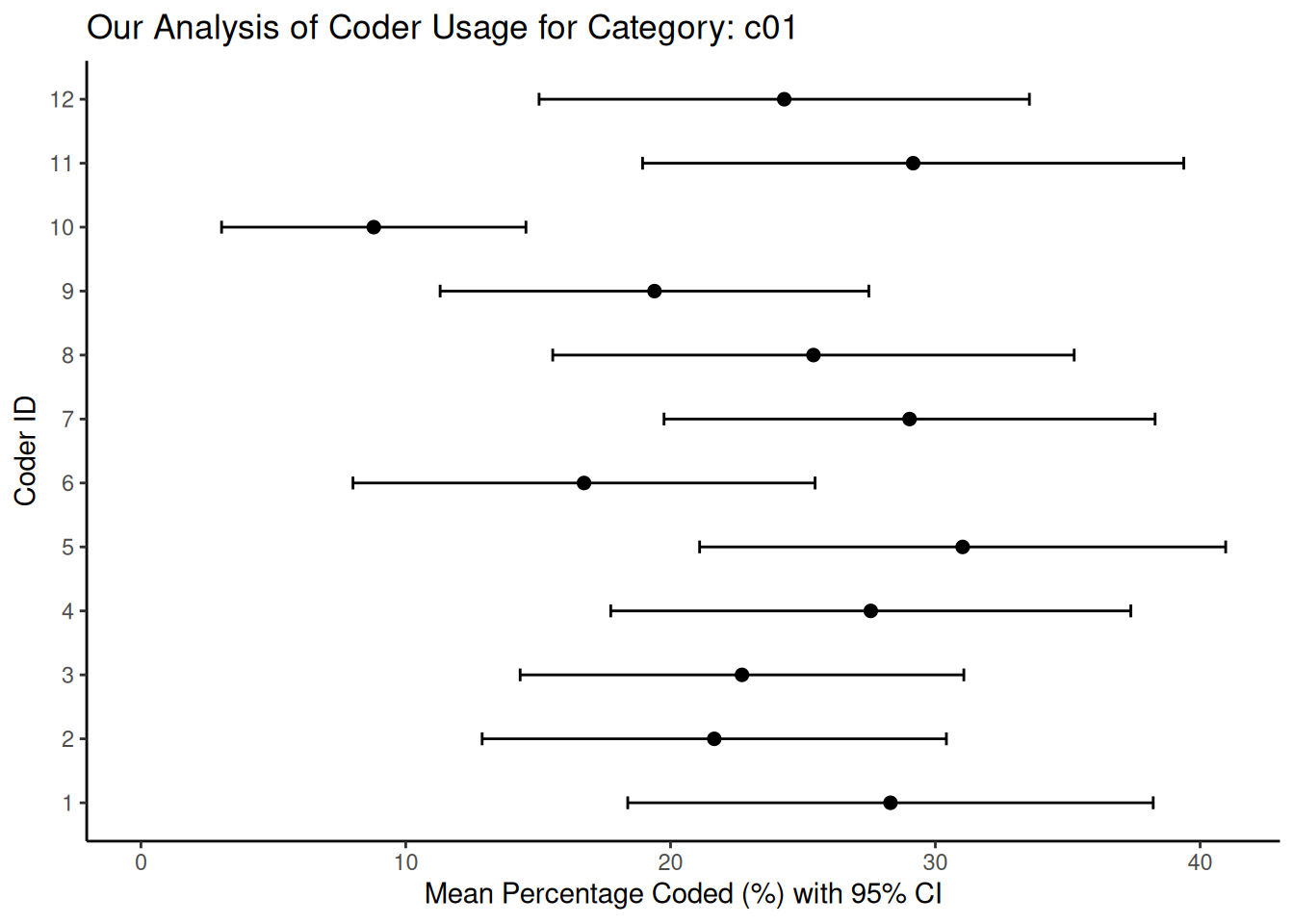
In these plots, the horizontal bars represent the 95% confidence intervals we derived from the bootstrap resampling process. When we see shorter bars around a coder’s mean percentage, this indicates high consistency (low uncertainty) in that coder’s use of that category relative to their overall coding activity. On the other hand, longer bars indicate greater uncertainty, which could be due to the coder’s less frequent or less consistent use of that particular category. When comparing between coders, overlapping confidence intervals indicate that the coders used the category at statistically similar rates. However, non-overlapping intervals may indicate systematic differences in how a particular coder interpreted or applied a category compared to their peers. Graphs such as these can help us identify specific categories or coders that contribute most to disagreement, and we can use them to improve our coder training or refine our coding scheme.