4.4 Import .csv Files
We can also choose not to import the texts into R in a direct fashion, but import a .csv file with word counts instead. One way to generate these counts is by using JFreq (Lowe, 2011). This stand-alone programme generates a .csv file where rows represent the documents and columns the individual words. The cells then contain the word counts for each word within each document. In addition, JFreq also allows for some basic pre-processing (though we would suggest you do this in R). Note that while JFreq is not under active maintenance, you can still find it at https://conjugateprior.org/software/jfreq/.
To use JFreq, open the programme and drag and drop all the documents you want to process into the window of the programme. Once you do this, the document file names will appear in the document window. Then, you can choose from several pre-processing options. Amongst these are options to make all words lower-case or remove numbers, currency symbols, or stop words. The latter are words that often appear in texts which do not carry important meaning. These are words such as ‘and’, ‘or’ and ‘but’. As stop words are language-specific and often context-specific as well, we need to tell JFreq what words are stop words. We can do so by putting all the stop words in a separate .txt file and load it in JFreq. You can also find many lists of stop words for different languages on-line (see, for example this collection). Finally, we can apply a stemmer which reduces words such as ‘Europe’ and ‘European’ to a single ’Europ*’ stem. JFreq allows us to use pre-defined stemmers by choosing the relevant language from a drop-down menu. Figure 4.1 shows JFreq while importing the .txt files of some electoral manifestos.
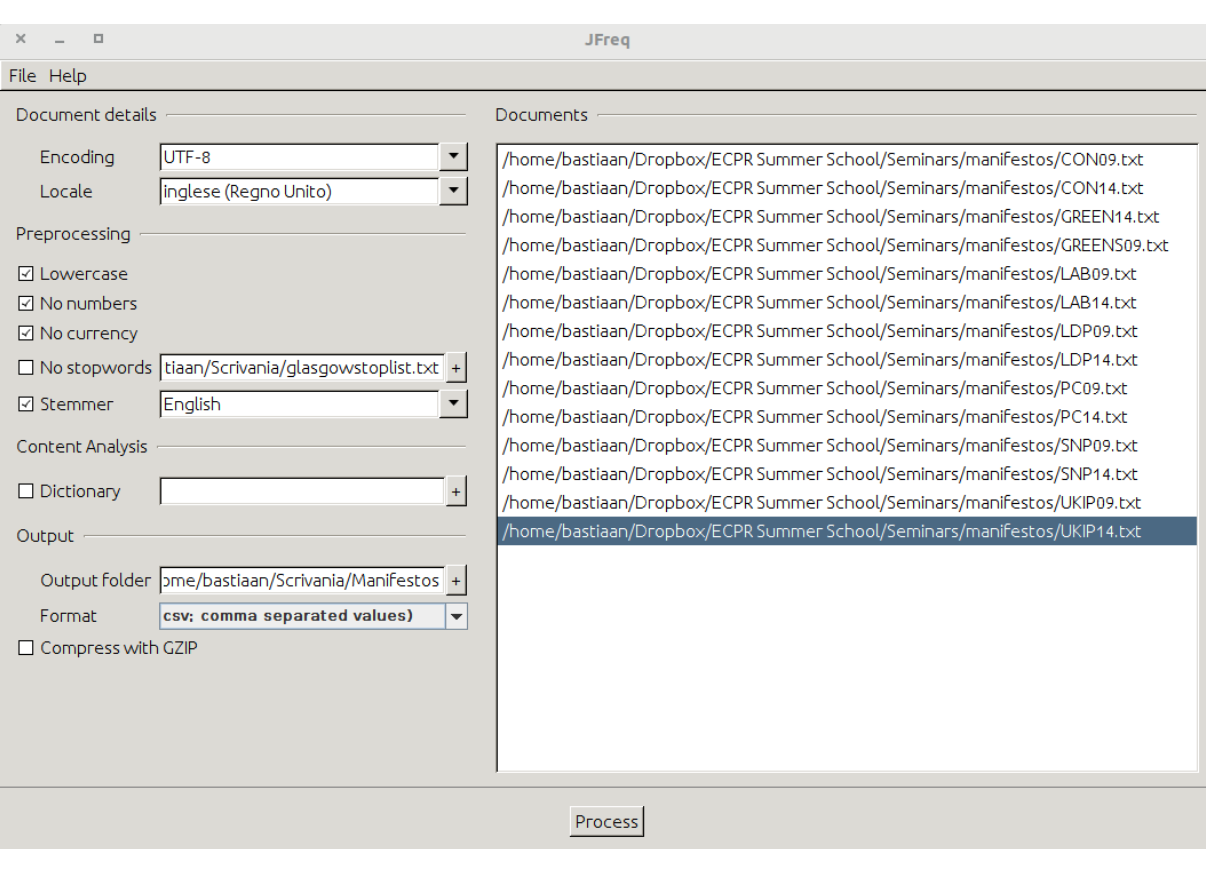
Figure 4.1: Overview of JFreq with several documents loaded
Note that here the encoding is UTF-8 while the locale is English (UK). Once we have specified all the options we want, we give a name for the output folder and press Process. Now we go to that folder we named and copy-paste the data.csv file into your Working Directory. In R, we then run the following:
By specifying row.names=1, we store the information of the first column in the data frame itself. This column contains the names of the documents, and belongs to the object of the data frame and does not appear as a separate column. The same is true for header=TRUE which ensures that the first row gives names to the columns (in this case containing the words).