11.2 Seeded Latent Dirichlet Allocation
An alternative to the above approach is one known as seeded-LDA. This approach uses seed words that can steer the LDA in the right direction. One origin of these seed words can be a dictionary that tells the algorithm which words belong together in various categories. To use it, we will first load the packages and set a seed:
Next, we need to specify a selection of seed words in dictionary form. While we can construct a dictionary ourselves, here we choose to use the Laver and Garry dictionary we saw earlier. We then use this dictionary to run our seeded LDA:
dictionary_LaverGarry <- dictionary(data_dictionary_LaverGarry)
seededmodel <- textmodel_seededlda(data_inaugural_dfm, dictionary = dictionary_LaverGarry)
terms(seededmodel, 20)## CULTURE ECONOMY ENVIRONMENT GROUPS INSTITUTIONS
## [1,] "people" "work" "civilization" "women" "president"
## [2,] "us" "government" "production" "race" "administration"
## [3,] "new" "can" "productive" "day" "executive"
## [4,] "america" "upon" "republic" "story" "continue"
## [5,] "nation" "great" "population" "thank" "office"
## [6,] "world" "must" "war" "back" "business"
## [7,] "must" "may" "order" "bless" "congress"
## [8,] "can" "shall" "produce" "president" "policy"
## [9,] "time" "economic" "tasks" "schools" "legislation"
## [10,] "let" "justice" "planet" "around" "law"
## [11,] "one" "opportunity" "products" "yes" "modern"
## [12,] "today" "children" "making" "across" "rule"
## [13,] "now" "country" "conditions" "hand" "authority"
## [14,] "every" "united" "productivity" "left" "race"
## [15,] "make" "war" "relations" "friends" "necessary"
## [16,] "americans" "progress" "promote" "began" "agencies"
## [17,] "american" "men" "maintained" "lost" "make"
## [18,] "years" "never" "understanding" "racial" "proper"
## [19,] "together" "economy" "leadership" "young" "reforms"
## [20,] "spirit" "made" "normal" "founding" "voices"
## LAW_AND_ORDER RURAL URBAN VALUES
## [1,] "force" "public" "man" "freedom"
## [2,] "determined" "law" "price" "history"
## [3,] "forces" "party" "sides" "human"
## [4,] "men" "permanent" "begin" "peace"
## [5,] "determination" "toward" "growth" "free"
## [6,] "day" "enforcement" "loyalty" "world"
## [7,] "court" "agricultural" "covenant" "nations"
## [8,] "counsel" "relations" "sick" "rights"
## [9,] "every" "direction" "compassion" "principles"
## [10,] "something" "nation" "final" "past"
## [11,] "evil" "establishment" "heal" "help"
## [12,] "mind" "islands" "globe" "life"
## [13,] "conviction" "countrymen" "goals" "faith"
## [14,] "terror" "stability" "passed" "strength"
## [15,] "necessity" "independence" "call" "live"
## [16,] "life" "feed" "understood" "know"
## [17,] "dealing" "provided" "suffer" "peoples"
## [18,] "body" "civilization" "trying" "security"
## [19,] "democratic" "agriculture" "mountains" "humanity"
## [20,] "determine" "ideals" "assure" "leadership"Note that using the dictionary has ensured that we only use the categories that occur in the dictionary. This means that we can look at which topics are in each inaugural speech and which terms were most likely for each of the topics. Let us start with the topics first:
topics <- topics(seededmodel)
topics_table <- ftable(topics)
topics_prop_table <- as.data.frame(prop.table(topics_table))
ggplot(data=topics_prop_table, aes(x=topics, y=Freq))+
geom_bar(stat="identity")+
labs(x="Topics", y="Topic Percentage")+
scale_y_continuous(expand = c(0, 0)) +
theme_classic()+
theme(axis.text.x = element_text(size=10, angle=90, hjust = 1))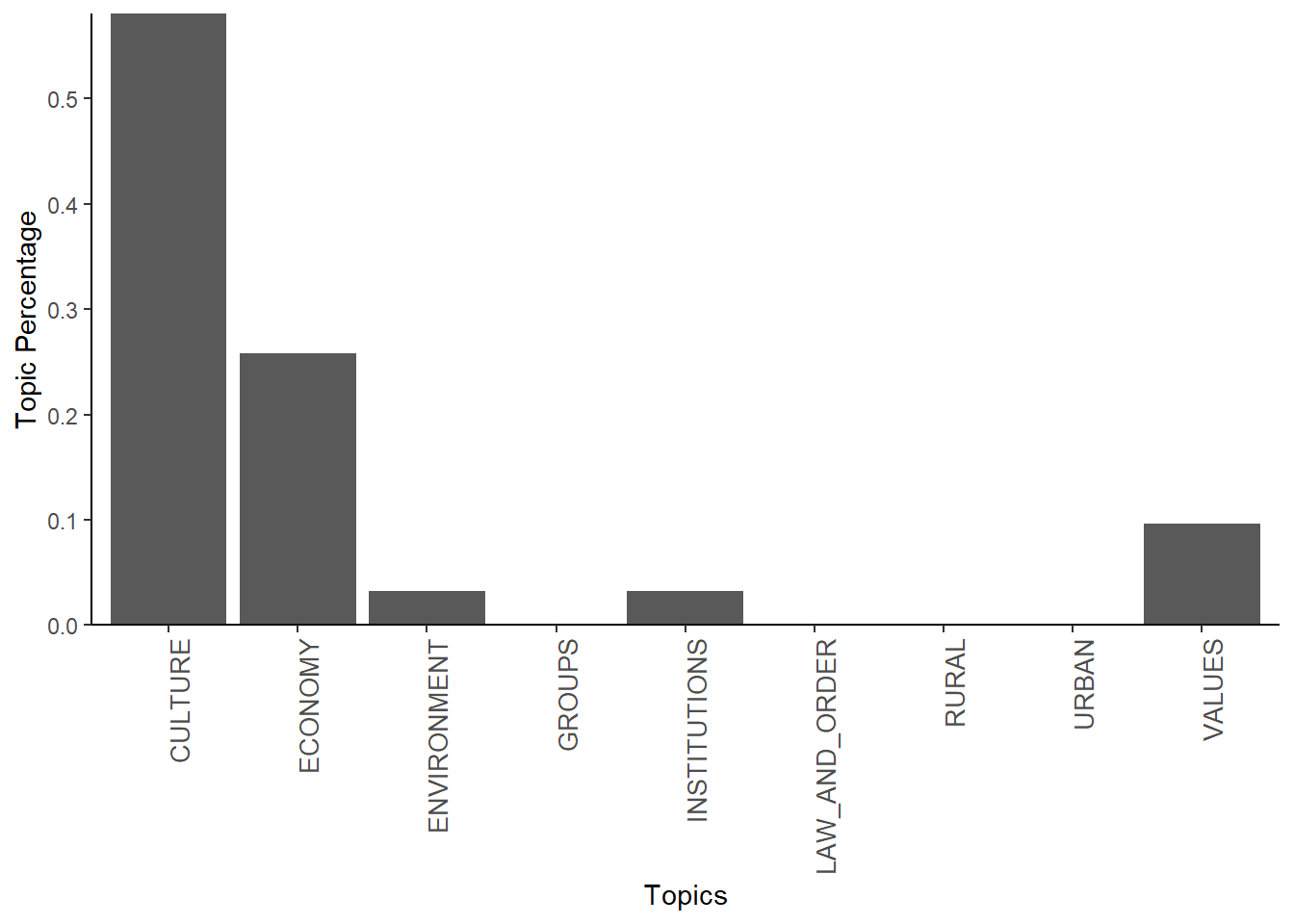
Here, we find that Culture was the most favoured topic, followed by the Economy and Values. Finally, we can then have a look at the most likely terms for each topic, sorted by each of the categories in the dictionary:
terms <- terms(seededmodel)
terms_table <- ftable(terms)
terms_df <- as.data.frame(terms_table)
head(terms_df)## Var1 Var2 Freq
## 1 A CULTURE people
## 2 B CULTURE us
## 3 C CULTURE new
## 4 D CULTURE america
## 5 E CULTURE nation
## 6 F CULTURE worldHere, we find that in the first cluster (denoted as ‘A’), the word ‘people’ was most likely (from all words that belonged to Culture). Thus, within this cluster, talking about culture often contained references to the people. In the same way, we can make similar observations for the other categories.