9.2 Wordfish
Different from Wordscores, for Wordfish we do not need any reference text. Instead of this, the method using a model (based on a Poisson distribution) to calculate the scores for the texts. The only thing we have to tell Wordfish is which texts define the extremes of our scale. While this might seems very practical, it also leaves us with a problem: which scale do we want? For example, let us have another look at the corpus of inaugural speeches of American presidents we saw earlier. What scale should we expect? Let us, for now, say that we care about a general left-right position. As benchmarks, we then set the 1965 Johnson speech as the most “left” and the 1985 Reagan speech as the most “right”. Also, we set a seed as the model draws random numbers and we want our work to be replicable:
set.seed(42)
library(quanteda)
data(data_corpus_inaugural)
corpus_inaugural <- corpus_subset(data_corpus_inaugural, Year > 1900)
data_inaugural_tokens <- tokens(
corpus_inaugural,
what = "word",
remove_punct = TRUE,
remove_symbols = TRUE,
remove_numbers = TRUE,
remove_url = TRUE,
remove_separators = TRUE,
split_hyphens = FALSE,
include_docvars = TRUE,
padding = FALSE,
verbose = TRUE
)
data_inaugural_tokens <- tokens_tolower(data_inaugural_tokens, keep_acronyms = FALSE)
data_inaugural_tokens <- tokens_select(data_inaugural_tokens, stopwords("english"), selection = "remove")
data_inaugural_dfm <- dfm(data_inaugural_tokens)
data_inaugural_dfm@Dimnames$docs
wordfish <- textmodel_wordfish(data_inaugural_dfm, dir = c(17,22))
summary(wordfish)Here, theta gives us the position of the text. As with Wordscores, we can also calculate the confidence intervals (note that theta is now called fit):
## $fit
## fit lwr upr
## 1901-McKinley 1.5264409 1.45790457 1.59497725
## 1905-Roosevelt 0.5506952 0.40261155 0.69877876
## 1909-Taft 2.1180136 2.08705631 2.14897090
## 1913-Wilson 0.9494614 0.84832377 1.05059905
## 1917-Wilson 0.8648796 0.75150283 0.97825636
## 1921-Harding 1.3071861 1.24655829 1.36781392
## 1925-Coolidge 1.4398978 1.38585947 1.49393615
## 1929-Hoover 1.5400830 1.48640261 1.59376344
## 1933-Roosevelt 1.1206324 1.03168956 1.20957530
## 1937-Roosevelt 0.6493799 0.54742236 0.75133754
## 1941-Roosevelt 0.1153382 -0.01421607 0.24489242
## 1945-Roosevelt -0.1670750 -0.36383112 0.02968117
## 1949-Truman 0.8432860 0.75602390 0.93054816
## 1953-Eisenhower 0.2792466 0.18725486 0.37123825
## 1957-Eisenhower 0.1574969 0.04465718 0.27033658
## 1961-Kennedy -0.5395875 -0.64994887 -0.42922607
## 1965-Johnson -0.7821091 -0.88376502 -0.68045324
## 1969-Nixon -0.9602454 -1.03699050 -0.88350021
## 1973-Nixon -0.4420077 -0.54461368 -0.33940174
## 1977-Carter -0.3423320 -0.46809663 -0.21656746
## 1981-Reagan -0.6953845 -0.77712614 -0.61364280
## 1985-Reagan -0.6413867 -0.71992268 -0.56285068
## 1989-Bush -0.8785297 -0.95604292 -0.80101647
## 1993-Clinton -1.1462836 -1.22477539 -1.06779189
## 1997-Clinton -0.8669737 -0.94358633 -0.79036108
## 2001-Bush -0.7438888 -0.84090471 -0.64687286
## 2005-Bush -0.4113008 -0.50479109 -0.31781044
## 2009-Obama -1.0807899 -1.14809049 -1.01348932
## 2013-Obama -1.0547830 -1.12762813 -0.98193782
## 2017-Trump -1.3804172 -1.45178196 -1.30905236
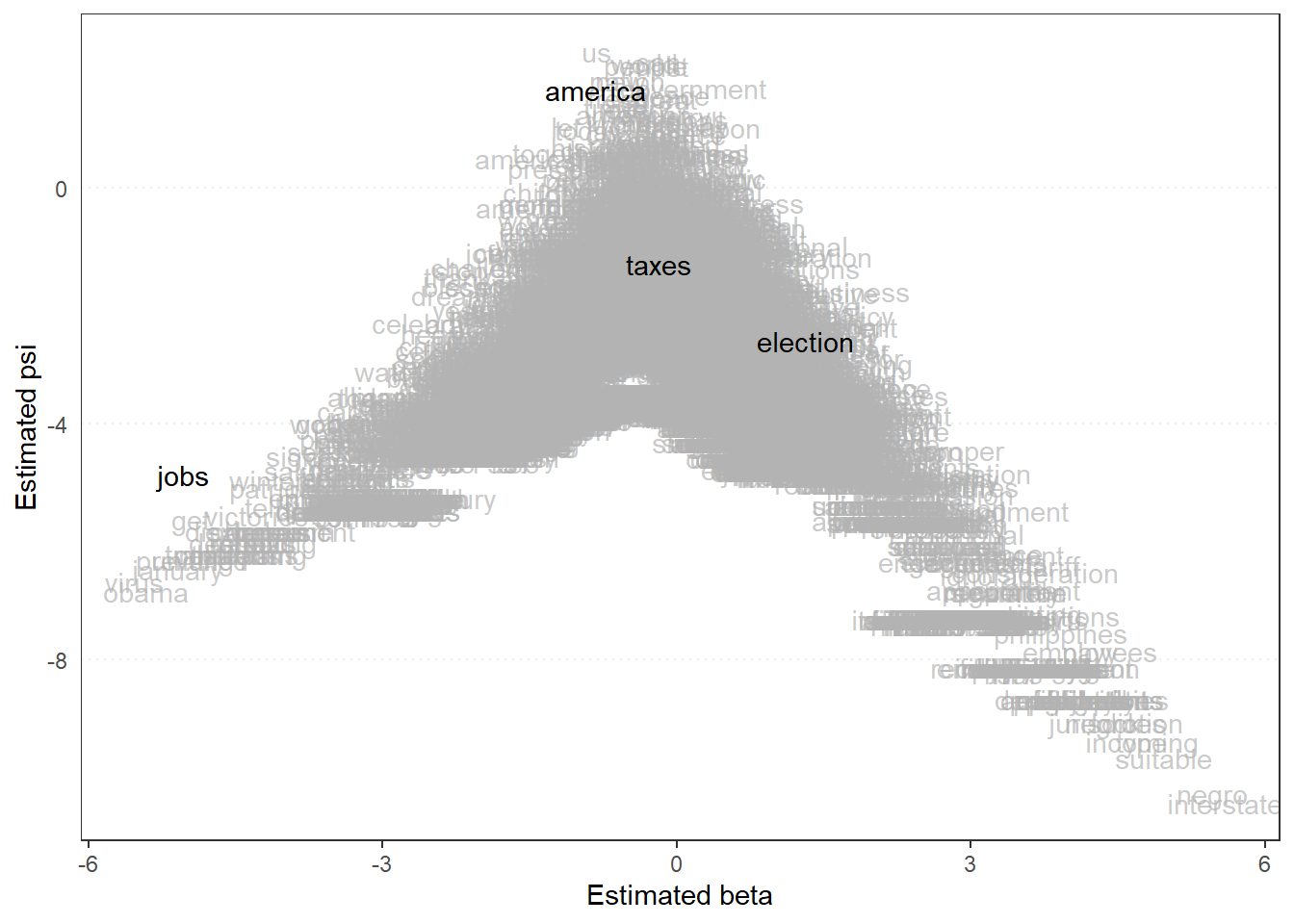
## 2021-Biden -1.3289432 -1.38772817 -1.27015814As with Wordscores, we can also plot graphs for Wordfish, using the same commands. The first graph we will again be looking at is the distribution of the words, which here forms an ‘Eifel Tower’-like graph:
textplot_scale1d(wordfish,
margin = "features",
highlighted = c("america","jobs","taxes","election")
)
And then we can do the same for the documents as well. Note that we can also make a similar graph to the one we made ourselves above (just replace pred_mv with pred_wordfish):
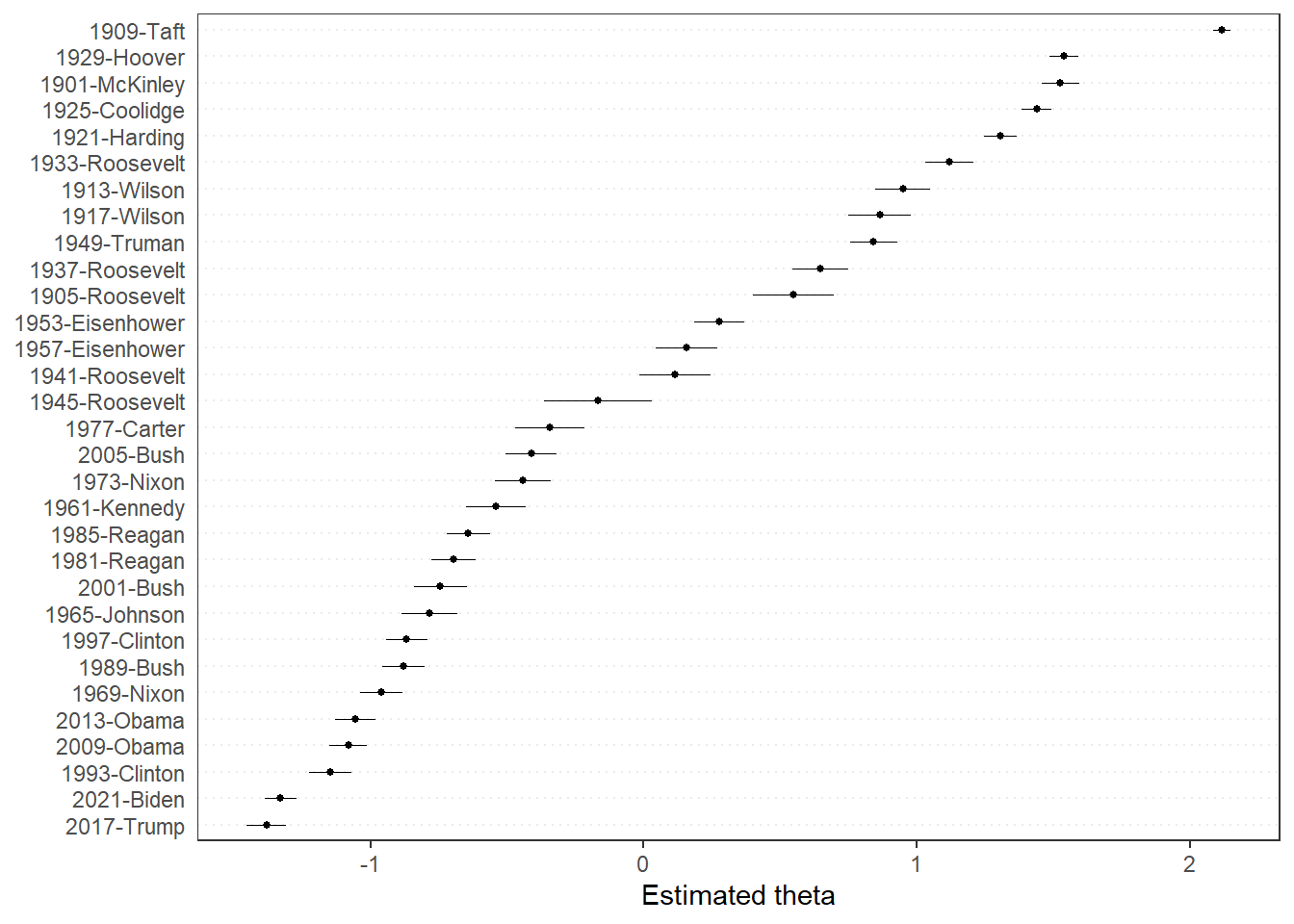
Looking at the results here gives us an interesting picture. Remember that we chose our benchmark texts to look at the left-right position of our texts? Here, we see that both these texts (the 1965 Johnson and 1985 Reagan) are quite close to each other. Sticking with our interpretation that Reagan is more right-wing than Johnson, this would mean that the 1909 Taft address was the most right-wing and the 2017 Trump text the most left-wing. Whether this is true is of course up to our interpretation.