9.1 Wordscores
The idea of Wordscores is to use reference texts (from which we know the position) to position our virgin texts (from which we do not know the position). Here, we aim to position the 2005 party manifestos of the five largest parties in the United Kingdom on a general left-right scale. For this, we will use the 2001 party manifestos of the same parties as reference texts. To know their positions, we will use the left-right scale from the 2002 Chapel Hill Expert Survey (Bakker et al., 2012) to do so. So, we load our data, make a subset, transform it into a dfm, and clean it:
library(quanteda)
library(quanteda.corpora)
data(data_corpus_ukmanifestos)
corpus_manifestos <- corpus_subset(data_corpus_ukmanifestos, Year == 2001 | Year == 2005)
corpus_manifestos <- corpus_subset(corpus_manifestos, Party=="Lab" | Party=="LD" | Party == "Con" | Party== "SNP" | Party== "PCy")
data_manifestos_tokens <- tokens(
corpus_manifestos,
what = "word",
remove_punct = TRUE,
remove_symbols = TRUE,
remove_numbers = TRUE,
remove_url = TRUE,
remove_separators = TRUE,
split_hyphens = FALSE,
include_docvars = TRUE,
padding = FALSE,
verbose = TRUE
)
data_manifestos_tokens <- tokens_tolower(data_manifestos_tokens, keep_acronyms = FALSE)
data_manifestos_tokens <- tokens_select(data_manifestos_tokens, stopwords("english"), selection = "remove")
data_manifestos_dfm <- dfm(data_manifestos_tokens)Then, we check the order of the documents inside our dfm:
## [1] "UK_natl_2001_en_Con" "UK_natl_2001_en_Lab" "UK_natl_2001_en_LD"
## [4] "UK_natl_2001_en_PCy" "UK_natl_2001_en_SNP" "UK_natl_2005_en_Con"
## [7] "UK_natl_2005_en_Lab" "UK_natl_2005_en_LD" "UK_natl_2005_en_PCy"
## [10] "UK_natl_2005_en_SNP"We can then set the scores for the reference texts. For the virgin texts, we set NA instead. Then, we run the wordscores model - providing the dfm and the reference scores - and save it into an object:
## Warning: package 'quanteda.textmodels' was built under R version 4.3.3scores <- c(7.72,5.18,3.82,3.2,3,NA,NA,NA,NA,NA)
ws <- textmodel_wordscores(data_manifestos_dfm, scores)
summary(ws)##
## Call:
## textmodel_wordscores.dfm(x = data_manifestos_dfm, y = scores)
##
## Reference Document Statistics:
## score total min max mean median
## UK_natl_2001_en_Con 7.72 7179 0 92 0.8646 0
## UK_natl_2001_en_Lab 5.18 16386 0 166 1.9735 0
## UK_natl_2001_en_LD 3.82 12338 0 101 1.4860 0
## UK_natl_2001_en_PCy 3.20 3508 0 72 0.4225 0
## UK_natl_2001_en_SNP 3.00 5692 0 108 0.6855 0
## UK_natl_2005_en_Con NA 4349 0 46 0.5238 0
## UK_natl_2005_en_Lab NA 13366 0 147 1.6098 0
## UK_natl_2005_en_LD NA 9263 0 109 1.1156 0
## UK_natl_2005_en_PCy NA 4203 0 148 0.5062 0
## UK_natl_2005_en_SNP NA 1508 0 49 0.1816 0
##
## Wordscores:
## (showing first 30 elements)
## time common sense conservative manifesto introduction
## 5.838 6.540 7.376 7.161 4.478 3.982
## lives raising family living safely earning
## 6.047 4.427 5.519 4.719 5.743 6.046
## staying healthy growing older knowing world
## 6.946 4.294 4.745 6.280 7.720 4.366
## leader stronger society town country civilised
## 4.524 4.910 4.342 7.515 4.401 4.278
## proud democracy conclusion present ambitious programme
## 6.069 5.267 6.946 3.594 4.466 4.233When we run the summary command, we can see the word scores for each word. This is the position of that word on our scale of interest. We then only need to figure out how often these words occur in each of the texts, add up their scores, and divide this by the total number of words of the texts. This gives us the raw score of the text. Yet, this raw score has some problems. Most important of which is that as some words occur in almost all texts, all the scores will be very clustered in the middle of our scale. To prevent this, we can spread out the scores again, so they look more like the scores of our reference texts. This rescaling has two versions. The first was the original as proposed by Laver et al. (2003), and focuses on the variance of the scores. The idea here is that the distribution of the scores of the virgin texts has the correct mean, but an incorrect variance that needs rescaling. The second, proposed by Martin & Vanberg (2008), focuses on the extremes of the scores. What it does is to take the scores of the virgin texts and stretch them out to match the extremes of the scores of the reference texts. Here, we run both so we can compare them. For the MV transformation, we will calculate the standard errors for the scores as well:
## Warning: 2187 features in newdata not used in prediction.## Warning: 2187 features in newdata not used in prediction.## Warning in predict.textmodel_wordscores(ws, rescaling = "mv", se.fit = TRUE, :
## More than two reference scores found with MV rescaling; using only min, max
## values.## UK_natl_2001_en_Con UK_natl_2001_en_Lab UK_natl_2001_en_LD UK_natl_2001_en_PCy
## 8.796502 5.438328 3.971706 1.921375
## UK_natl_2001_en_SNP UK_natl_2005_en_Con UK_natl_2005_en_Lab UK_natl_2005_en_LD
## 2.169511 5.657514 5.126266 5.045241
## UK_natl_2005_en_PCy UK_natl_2005_en_SNP
## 3.752780 4.289562## $fit
## fit lwr upr
## UK_natl_2001_en_Con 7.720000 7.633905 7.806095
## UK_natl_2001_en_Lab 5.328179 5.292403 5.363955
## UK_natl_2001_en_LD 4.283594 4.242225 4.324963
## UK_natl_2001_en_PCy 2.823268 2.748279 2.898257
## UK_natl_2001_en_SNP 3.000000 2.932911 3.067089
## UK_natl_2005_en_Con 5.484291 5.386166 5.582417
## UK_natl_2005_en_Lab 5.105916 5.057239 5.154593
## UK_natl_2005_en_LD 5.048207 4.985890 5.110523
## UK_natl_2005_en_PCy 4.127666 4.038006 4.217325
## UK_natl_2005_en_SNP 4.509983 4.321648 4.698318
##
## $se.fit
## UK_natl_2001_en_Con UK_natl_2001_en_Lab UK_natl_2001_en_LD UK_natl_2001_en_PCy
## 0.04392699 0.01825342 0.02110697 0.03826022
## UK_natl_2001_en_SNP UK_natl_2005_en_Con UK_natl_2005_en_Lab UK_natl_2005_en_LD
## 0.03422976 0.05006496 0.02483581 0.03179478
## UK_natl_2005_en_PCy UK_natl_2005_en_SNP
## 0.04574545 0.09609115Note that this does not only predict the 2005 texts, but also the 2001 texts. As such, we can use these scores to see how well this procedure can recover the original scores. One reason why this might be a problem is because of a warning you most likely received. This says that ‘n features in newdata not used in prediction’. This is as the method does not use all the words from the reference texts to score the virgin texts. Instead, it only uses the words that occur in them both. Thus, when we compare the reference scores with the scores the method gives to the reference documents, can see how well the method does.
To compare the scores, we will use the Concordance Correlation Coefficient as developed by Lin (1989). This coefficient estimates how far two sets of data deviate from a line of 45 degrees (which indicates perfect agreement). To calculate this, we take the scores (here we take the LBG version) from the object we created and combine them with the original scores. From this, we only select the first five texts (those from 2001) and calculate the CCC:
comparison <- as.data.frame(cbind(pred_lbg, scores))
comparison <- comparison[1:5, ]
CCC(comparison$scores, comparison$pred_lbg, ci = "z-transform", conf.level = 0.95,
na.rm = TRUE)## $rho.c
## est lwr.ci upr.ci
## 1 0.9239214 0.8243074 0.9680456
##
## $s.shift
## [1] 1.444046
##
## $l.shift
## [1] -0.05943275
##
## $C.b
## [1] 0.9345458
##
## $blalt
## mean delta
## 1 8.258251 -1.0765018
## 2 5.309164 -0.2583283
## 3 3.895853 -0.1517065
## 4 2.560688 1.2786249
## 5 2.584755 0.8304892The result here is not bad, though the confidence intervals are rather large. We can have a further look at why this is the case by plotting the data. In this plot, we will show the position of the texts, as well as a 45-degree line. Also, we plot the reduced major axis, which shows the symmetrical relationship between the two variables. This line is a linear regression, which we compute first using the lm command:
library(ggplot2)
lm_line <- lm(comparison$scores ~ comparison$pred_lbg)
ggplot(comparison, aes(x=scores, y=pred_lbg)) +
geom_point()+
xlab("Original Scores")+
ylab("LBG Scores")+
ylim(0, 12)+
xlim(0, 12)+
geom_abline(aes(intercept = 0,
slope =1,
linetype = "dashed"))+
geom_abline(aes(intercept = lm_line$coefficients[1],
slope = lm_line$coefficients[2],
linetype = "solid" ))+
scale_shape_manual(name = "",
values=c(1,3),
breaks=c(0,1),
labels=c("Line of perfect concordance" , "Reduced major axis"))+
scale_linetype_manual(name = "",
values=c(1,3),
labels=c("Line of perfect concordance" , "Reduced major axis"))+
theme_classic()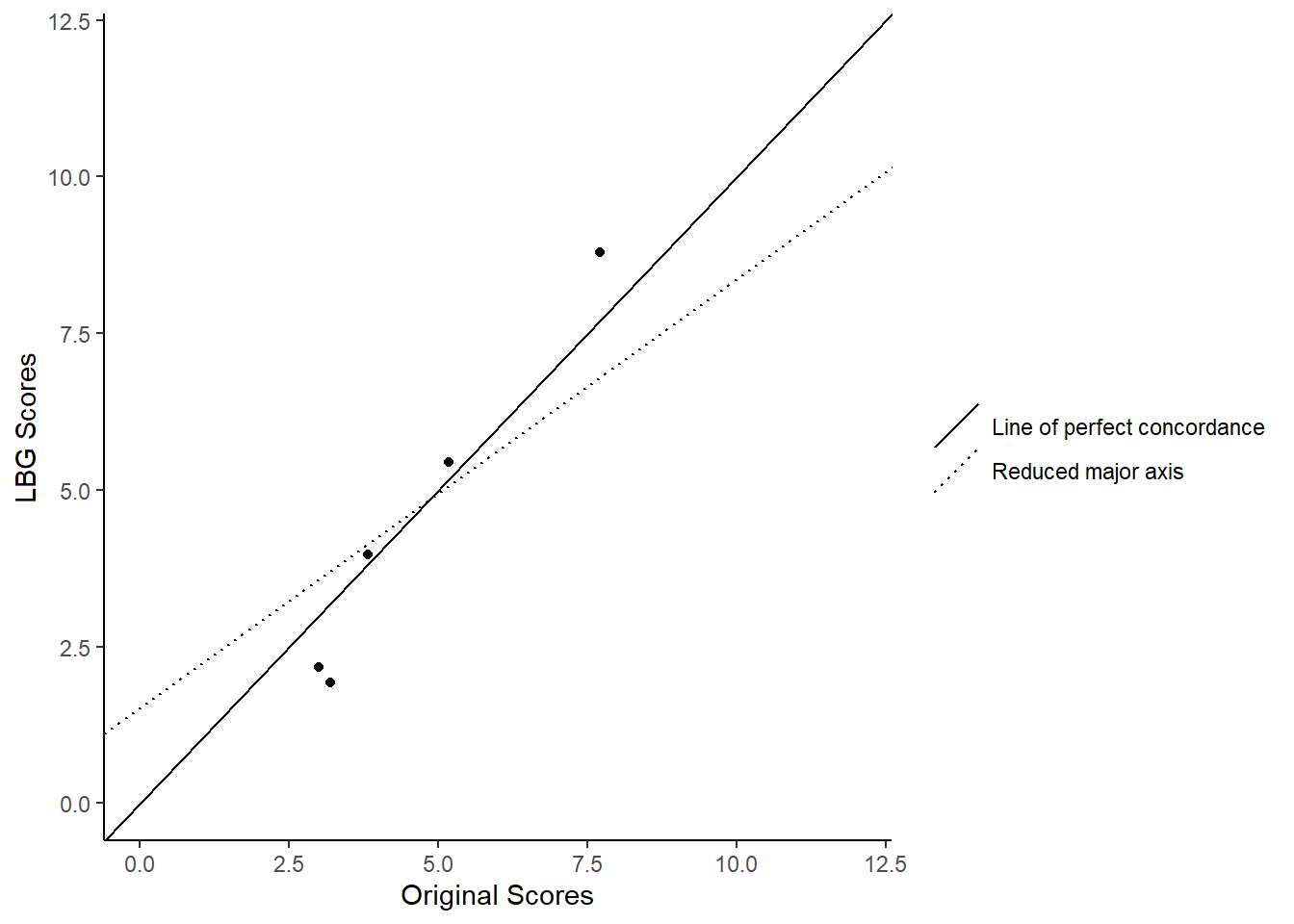
This graph allows us to spot the problem. That is that while we gave the manifesto for Plaid Cymru (PCy) a reference score of 3.20, Wordscores gave it 1.91. Removing this manifesto from our data-set would thus improve our estimates.
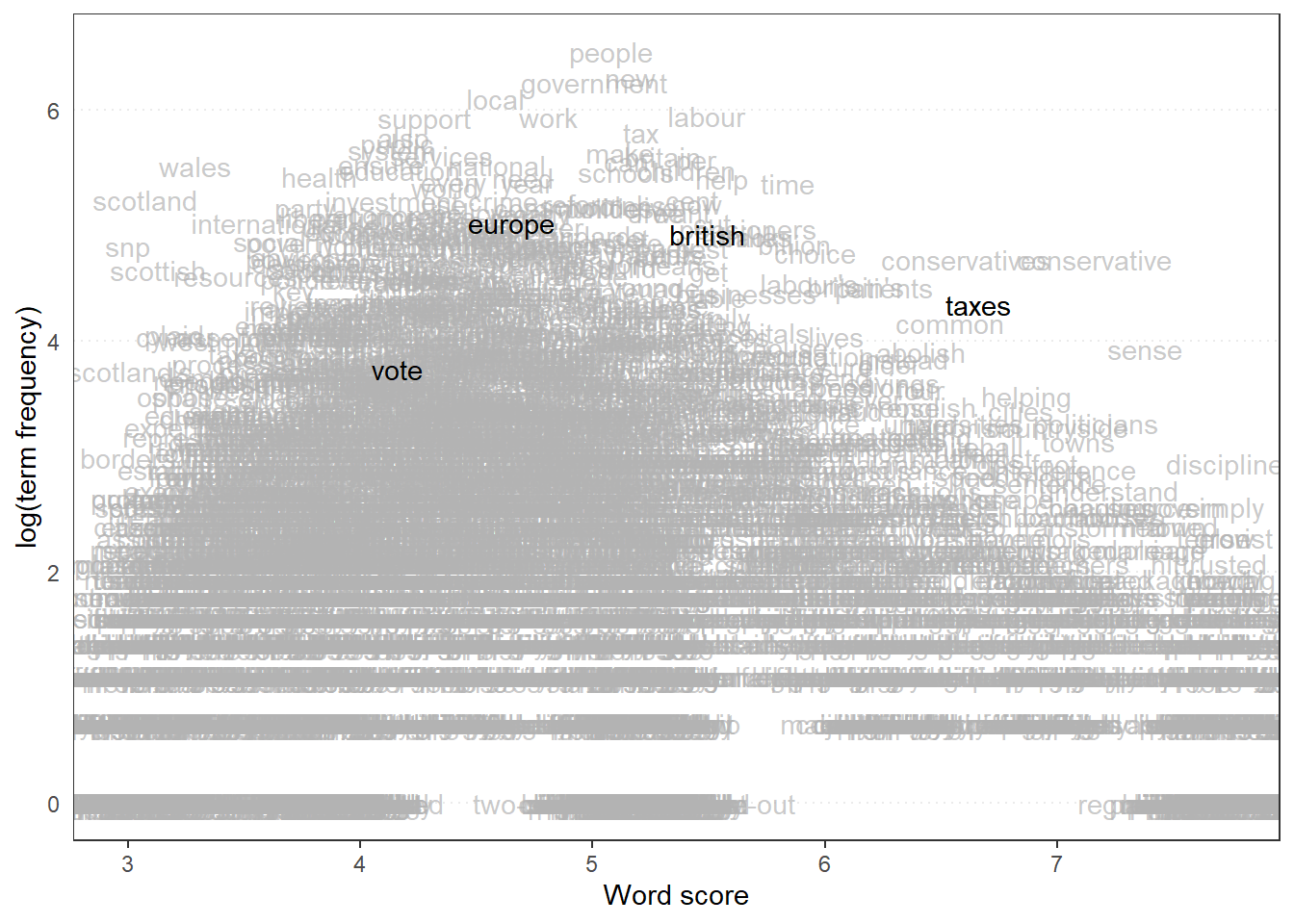
Apart from positioning the texts, we can also have a look at the words themselves. We can do this with the textplot_scale1d command, for which we also specify some words to highlight:
library(quanteda.textplots)
textplot_scale1d(ws,
margin = "features",
highlighted =c("british","vote", "europe", "taxes")
)
Finally, we can have a look at the confidence intervals around the scores we created. For this, we use the same command as above, though instead of specifying features (referring to the words), we specify texts. Note that we can only do this for the MV scores, as only here we also calculated the standard errors:
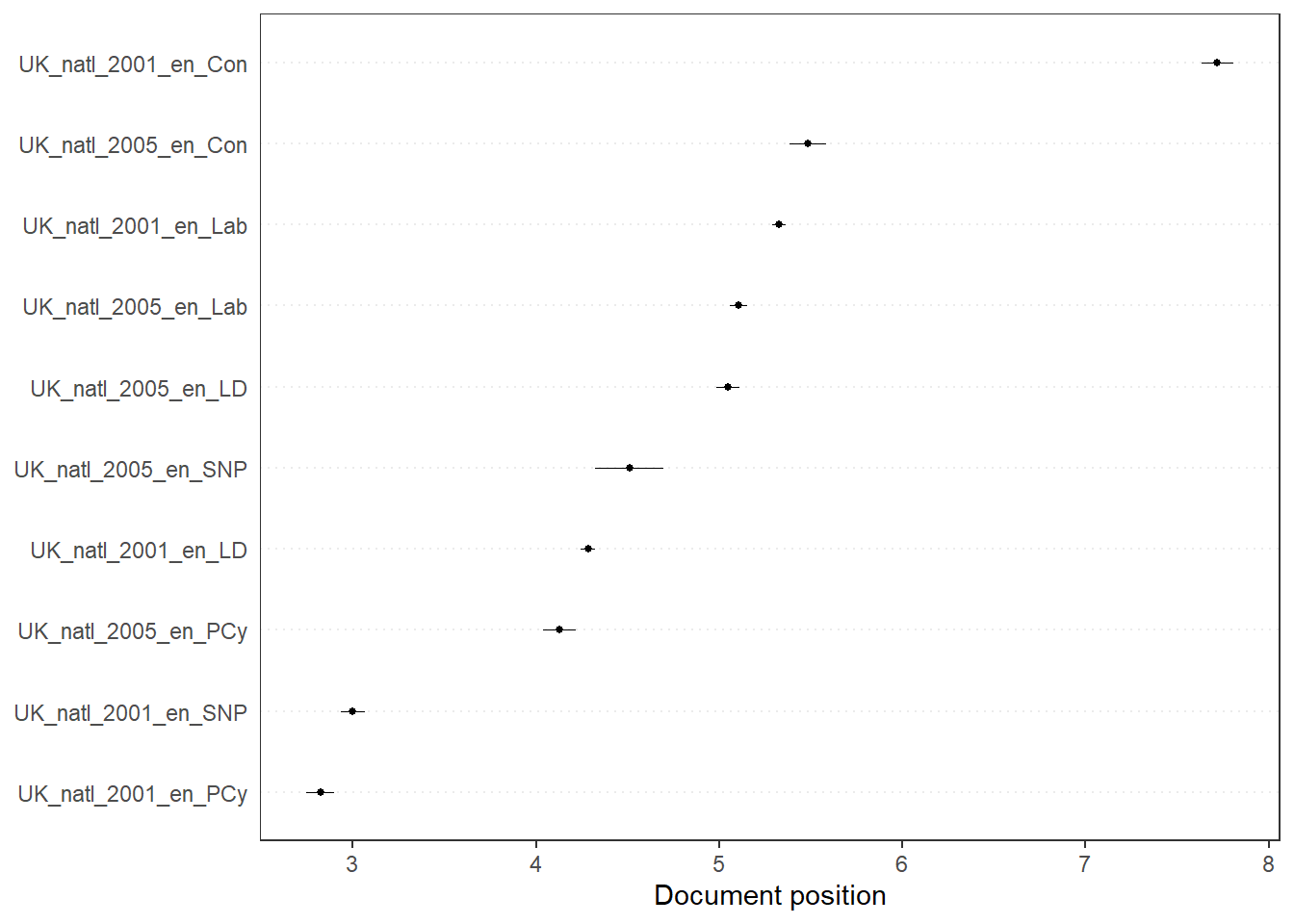
Note that we can also make this graph ourselves. This requires some data-wrangling using the dplyr package. This package allows us to use pipes, denoted by the %>% command. This pipe transports an output of a command to another one before saving it. This saves us from constructing too many intermediate data sets. Thus, here we first bind together the row names of the fit (which denotes the documents), the fit itself, and the standard error of the fit (which also includes the lower and upper bound). We then transform this into a tibble (similar to a data frame), rename the first and fifth columns, and finally ensure that all the values (which are still characters) are numeric (and year a factor):
library(dplyr)
data_textplot <- cbind(rownames(as.data.frame(pred_mv$se.fit)), pred_mv$fit, pred_mv$se.fit) %>%
as_tibble() %>%
rename(id = 1, se = 5) %>%
mutate(fit = as.numeric(fit),
lwr = as.numeric(lwr),
upr = as.numeric(upr),
se = as.numeric(se),
year = as.factor(stringr::str_sub(id, start = 9, end = 12)))If we now look at our data_textplot object, we see that we have all the data we need: the fit (the average value), the lower and upper bounds, the year and the id that tells us with which party and year we are dealing. The only thing that remains is to give the parties better names. To see the current ones, type data_textplot$id in the console. We can then give them different names (ensure that the order remains the same). We then sort them in decreasing order based on their fit:
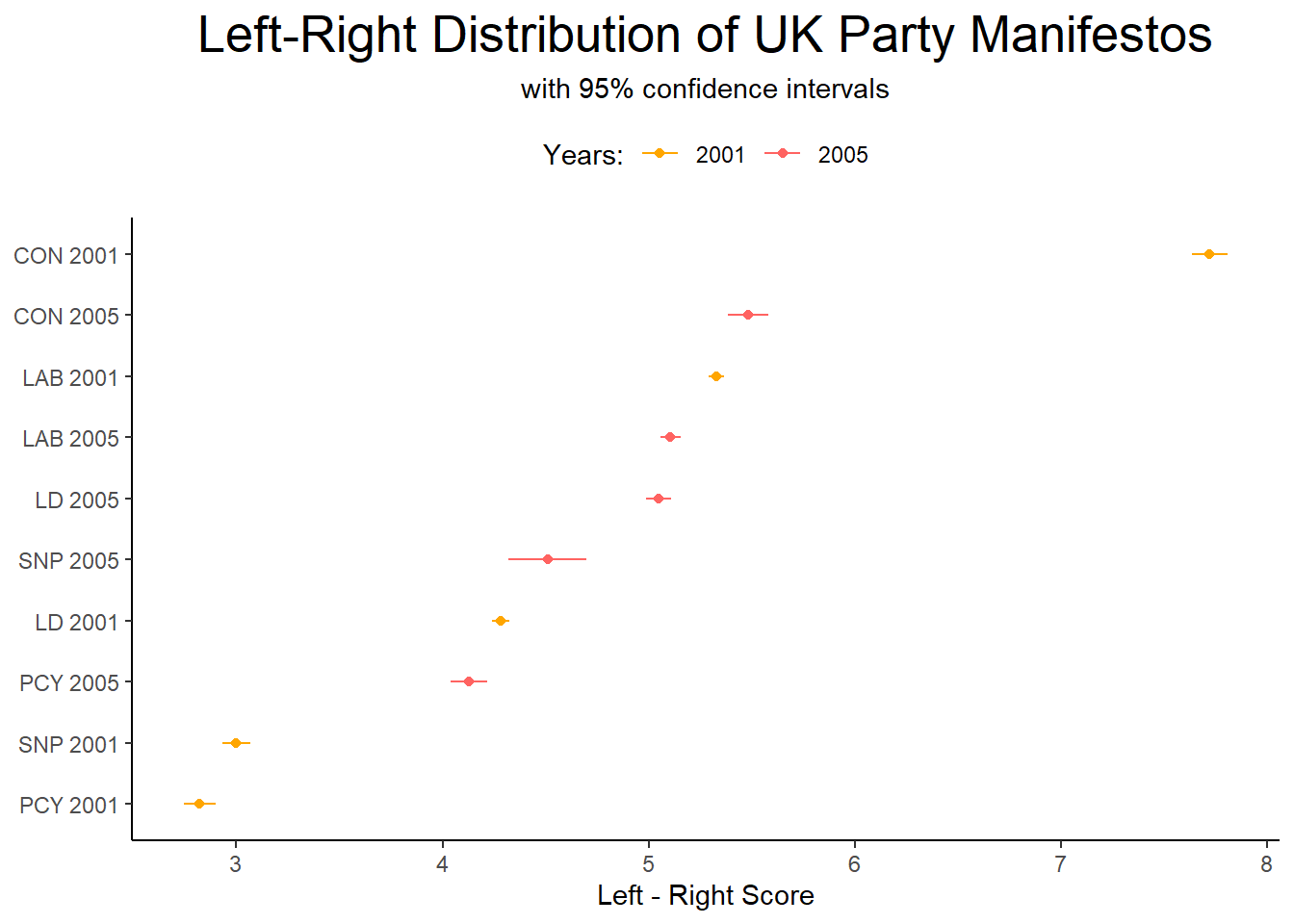
data_textplot$id <- as.character(c("CON 2001", "LAB 2001", "LD 2001", "PCY 2001", "SNP 2001", "CON 2005","LAB 2005", "LD 2005","PCY 2005", "SNP 2005"))
data_textplot$id <- with(data_textplot, reorder(id, fit))Then, we can plot this data using ggplot:
ggplot() +
geom_point(data = data_textplot,
aes(x = fit, y = id, colour = year)) +
geom_errorbarh(data = data_textplot,
aes(xmax = upr, xmin = lwr, y = id, colour = year),
height = 0) +
theme_classic() +
scale_colour_manual(values = c("#ffa600", "#ff6361"),
name = "Years:",
breaks = c("2001", "2005"),
labels = c("2001", "2005")) +
labs(title = "Left-Right Distribution of UK Party Manifestos",
subtitle = "with 95% confidence intervals",
x = "Left - Right Score",
y = NULL) +
theme_classic()+
theme(plot.title = element_text(size = 20, hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
legend.position = "top")